Problem Statement
We present a model that renders and extracts features from 3D scenes that contain transparent objects. There are existing datasets of transparent objects and methods to render transparent objects, such as KeyPose and Dex-NeRF. However, few approaches render and extract transparent objects from scenes. As a result, we propose a method that involves training TensoRF instead of NeRF on a dataset of transparent objects for faster scene rendering. We employ feature field distillation to relate regions of a scene with their features, so that we can render specific features within a scene. We qualitatively evaluate the renderings of the transparent objects. Through this work, we hope to test the limits of neural rendering models and expand upon the types of objects that these algorithms can reconstruct.
Related Work
We will extend the work of “Decomposing NeRF for Editing via Feature Field Distillation”. To mitigate the limitations present in other works, the paper introduces Distilled Feature Fields (DFFs) to locally edit scenes rendered by NeRF. DFFs map a coordinate x and a viewing direction d to a density, color, and feature. The way DFFs are trained is by minimizing the difference between the features rendered by NeRF and features that are predicted by a pre-trained 2D image feature encoder. In addition, the difference between the rendered and ground-truth pixel colors is also minimized. The pre-trained feature encoders that the paper uses are LSeg and DINO.
Without a pre-trained feature extractor, it is difficult to make localized, query-based edits on specific objects in the 3D scene. This is because scenes rendered by NeRF are implicitly encoded in the weights of an MLP or voxel grid and are not object-centric. An example of this occurs in CLIP-NeRF, which is a model that uses CLIP to edit NeRF renderings using text prompts. CLIP is a neural network with zero-shot performance that learns relationships between visual concepts and natural language. However, CLIP-NeRF often edits additional regions unrelated to the object specified by the text query. Some works also reconstruct scenes with more constrained representations with domain or situation specific pipelines. However, this limits the types of scenes and objects that can be edited.
Therefore, "Decomposing NeRF for Editing via Feature Field Distillation" uses DINO and LSeg as feature encoders for their DFF model. DINO is a model that uses self-supervised learning to semantically segment 2D images. The model works by using self-distillation, a method that uses teacher and student networks. In the forward pass, the teacher and student networks receive two different crops of the image as an input. The output of the teacher network is centered, and both the teacher and student network outputs are passed through softmax and loss functions. During backpropagation, only the student's weights are updated. The teacher's weights are updated by applying an exponential moving average on the student's weights.
LSeg (Language-Driven Semantic Segmentation) is a zero-shot semantic image segmentation model. Traditional semantic segmentation models require labeled training data which is usually created by human annotators. This process is both time and labor intensive, and it is also prone to human-errors. Some zero-shot segmentation models use standard word embeddings while focusing on the image encoder. LSeg improves upon zero-shot semantic segmentation by using the CLIP model to train an image encoder to produce input image embeddings that are similar to the corresponding label embeddings produced by the text encoder.
Although NeRF renderings are used in some of the mentioned papers, it is time-consuming to train and can take up to several days to model a single scene. To mitigate this, TensoRF decomposes 4D radiance field tensors into multiple low-rank tensors to enable faster reconstruction and higher quality renderings than NeRF.
Work on rendering transparent objects is limited. Dex-NeRF uses NeRF to render the geometry of transparent objects to improve robot manipulation. The authors of Dex-NeRF have also created a publicly available dataset of real and synthetic transparent objects in real-world settings. While Dex-NeRF improves rendering scenes with transparent objects, it does not enable editing of scenes containing transparent objects.
Method
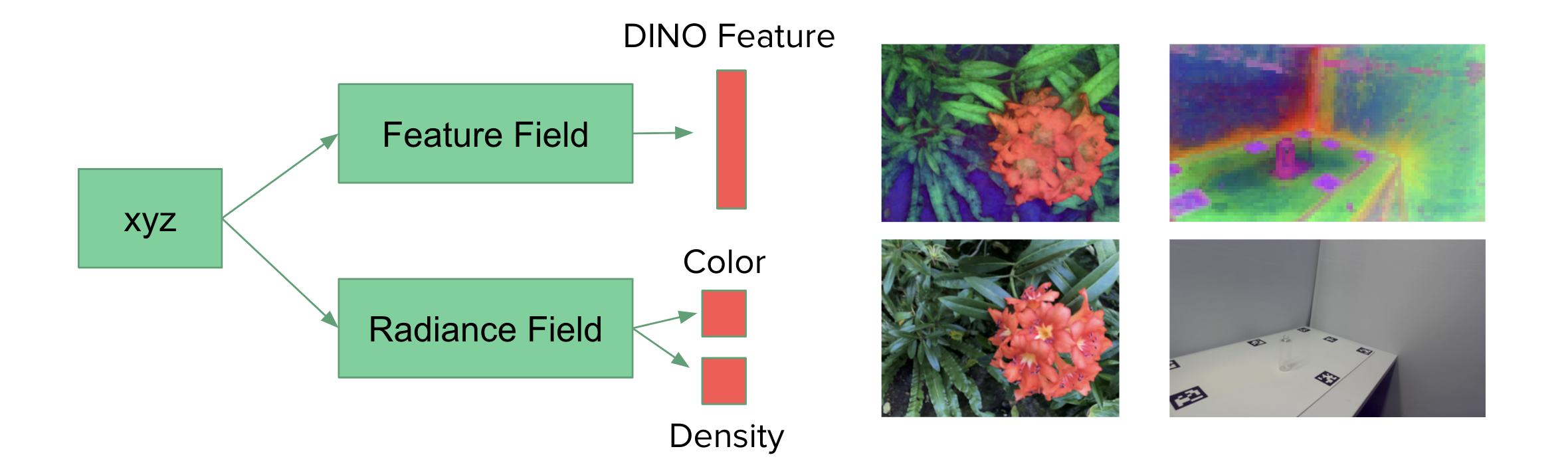
Feature and Radiance Fields
The radiance field was trained on the LLFF flower images. Given an input of a sampled 3D point, the radiance field outputs the color and density. The feature field was trained using the DINO feature representation for each image, which was obtained from extracting visual descriptors from this implementation. Given a sampled 3D point as input, the feature field outputs the DINO feature at that point.
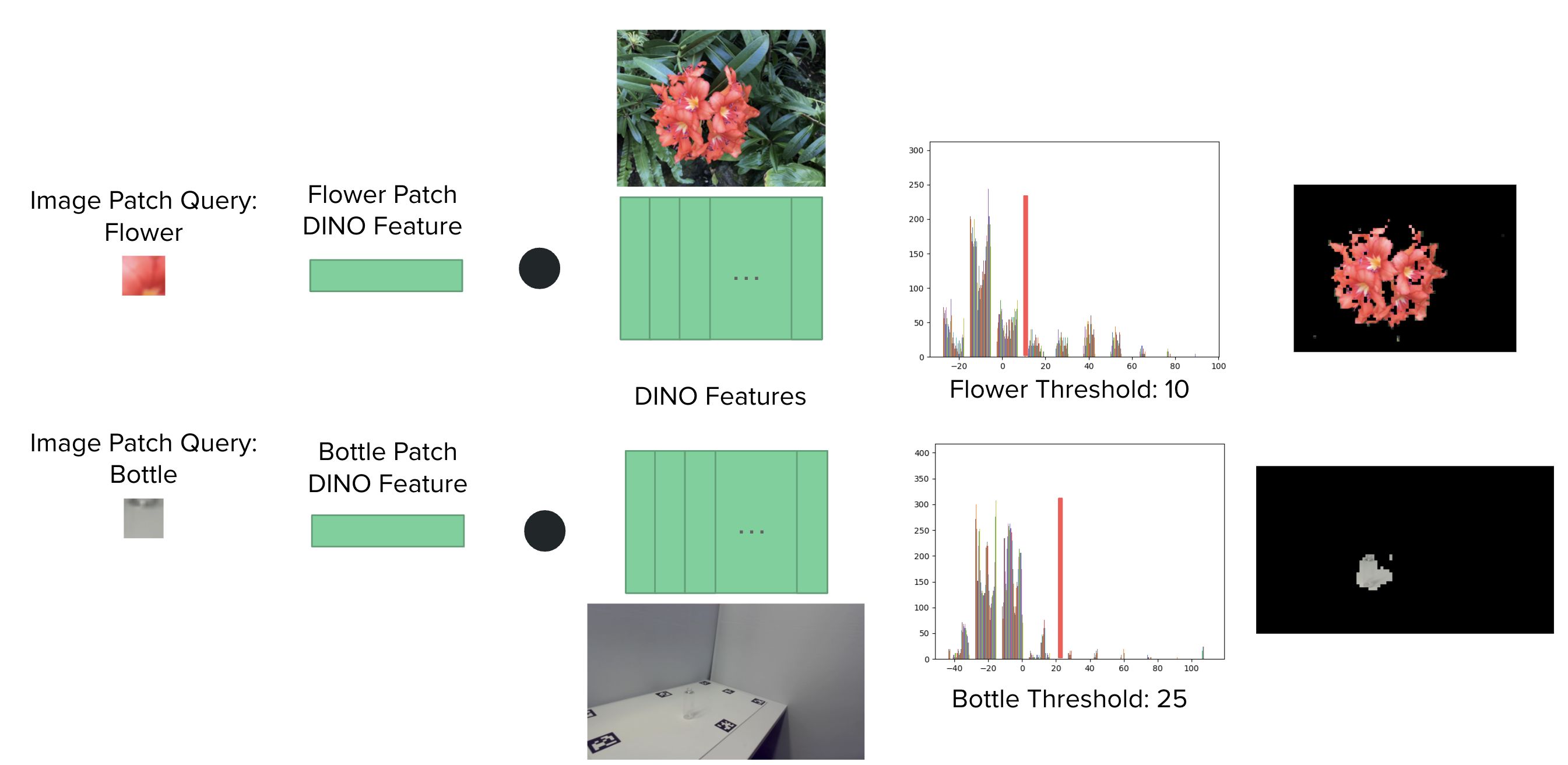
2D Scene Decomposition
Eventually, we want to use the feature field to extract and render specific objects from a 3D scene. First, we implemented 2D scene decomposition to ensure that we can extract a specific object from a 2D image, before we apply similar logic to implement this in the 3D case. During 2D scene decomposition, we select an image patch query of the feature of interest (ex. flower, bottle) and get the DINO feature vector corresponding to the pixels in the image patch. We also have the DINO feature vectors for the entire image. To find the pixels in the image that would match the image patch, we compute the dot product between the patch feature vector and the feature vectors from the image. This results in a list of values corresponding to each pixel in the image. These values would be greater for pixels that are more similar to the patch. To extract the features most similar to the patch, we find a threshold that extracts the desired object from the patch in the image. This was obtained from plotting the distribution of thresholds and querying for thresholds that separate modes of the distribution. We keep the RGB values for the values that are above the threshold. For values below the threshold, we set the RGB values to 0. As a result, the flower in the image is extracted, and the background and leaves are set to 0. In the transparent object case, the bottle is extracted. However, some parts of the shadow were extracted because the feature vector was very similar for the bottle and its shadow. Further work can be done on isolating the bottle from its shadow.
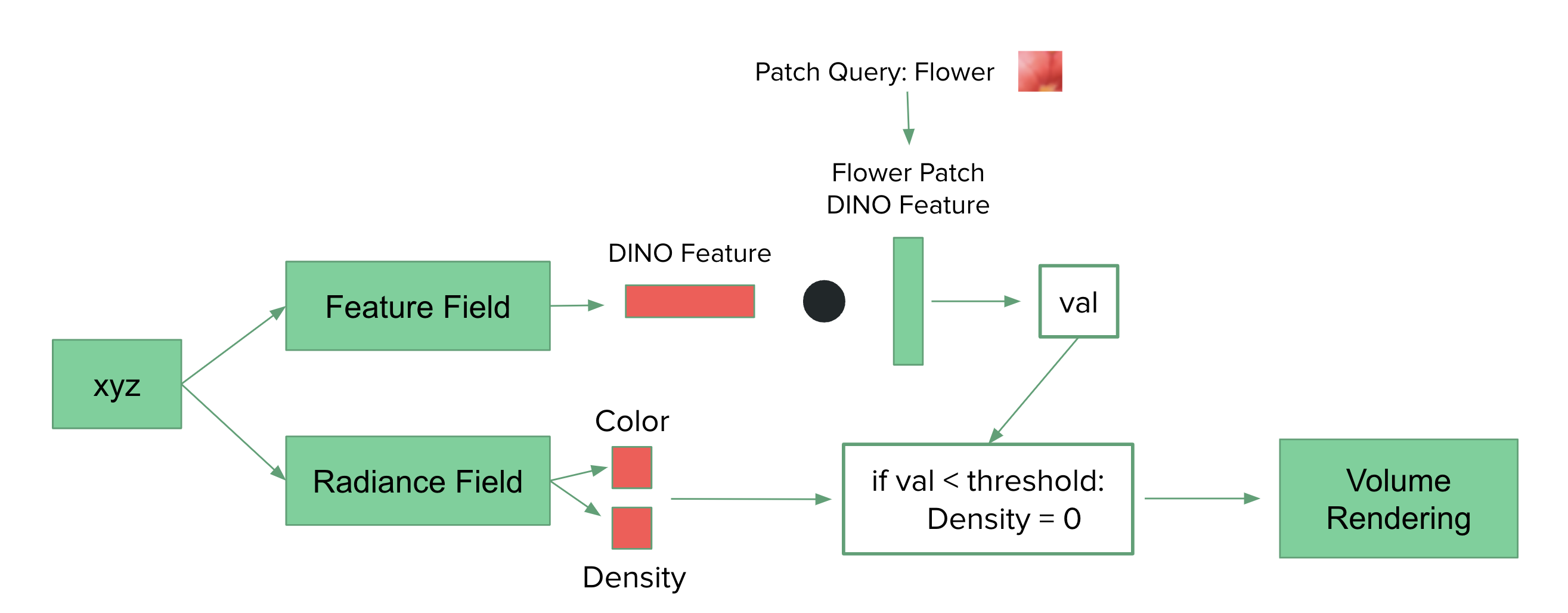
3D Scene Decomposition
Similar to 2D scene decomposition, we apply a similar mechanism for 3D scene decomposition. For each sampled point, we apply the feature and radiance fields. The feature field outputs the DINO feature feature at that point, and we compute a dot product between the DINO feature and the patch query feature. In this case, the patch query is the DINO feature representing a section of the flower. The radiance field outputs the color and density at the sampled point. If the value of the dot product is less than the threshold, we set the density to 0. Otherwise, we keep the density output from the radiance field as is. As a result, only the areas corresponding to the feature in the selected patch will be rendered. In this case, the flower will be rendered.
Results
Rendering 3D Flower Scene (Opaque)
As an initial experiment, we use the flower images from the LLFF dataset to render the scene using vanilla TensoRF. No changes were made to the TensoRF codebase to generate this result.
Extracting Features from 2D Flower Image (Opaque)

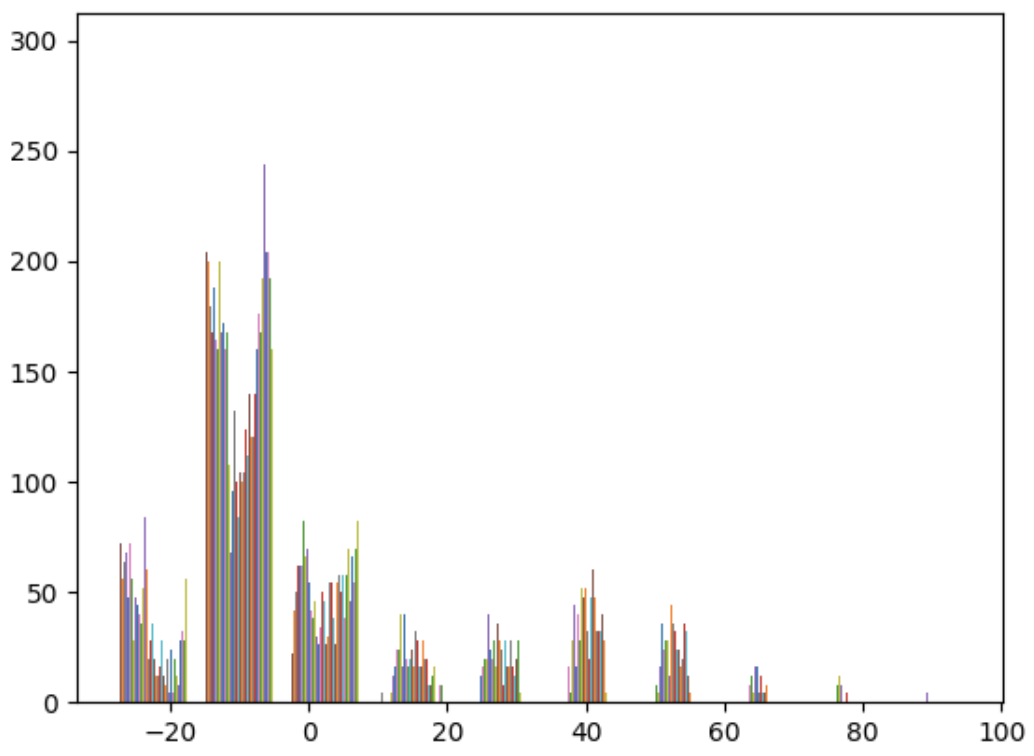
In order to extract objects from the 2D flower image, we used the DINO feature extractor to obtain the features at the 11th layer of the model. We extract the features corresponding to the flower in the image by calculating a dot product between a known flower patch feature and all features in the image. Using the histogram of dot product results, we select a threshold for values that correspond to the flower. We choose a threshold of 10 for the flower and change the pixels whose dot products are lower than the threshold to be black. In addition, we extracted the leaf feature from the same image using a threshold of 15, as shown below.

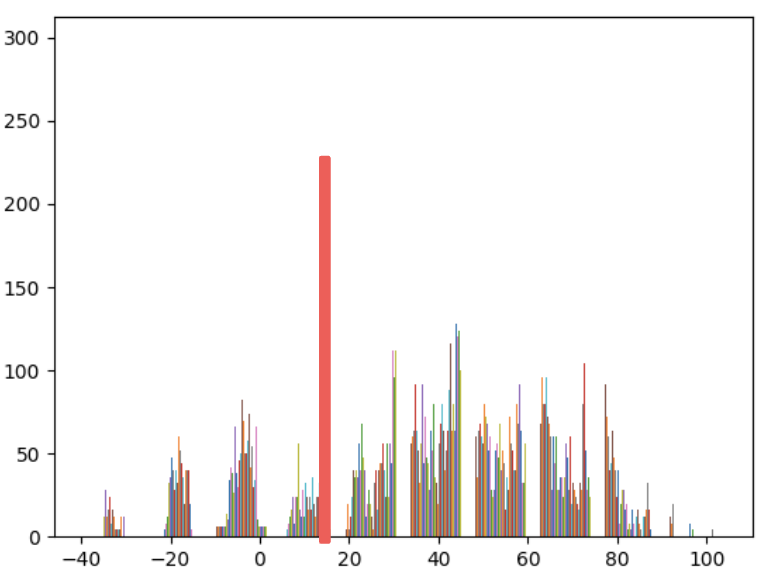
Extracting and Rendering Features from 3D Flower Scene (Opaque)
We attempted to extract and only render the flower features from the scene. Due to computation constraints, we only render a limited number of views using our trained feature and radiance fields. We show the distribution of the dot product values between the patch flower feature and the DINO features from the feature field in the figure below, and we determined different thresholds using this histogram. Below are the video results from two thresholds. As shown in the videos, the threshold of -0.5 removes more of the background features. However, it also removes some unintended pixels of the flower in the scene. On the other hand, the threshold of -1 keeps more of the pixels with the flower, but it also does not remove the non-flower pixels. We hope to try out additional thresholds in the future to better extract the flower features, as well as render the scene using more views.
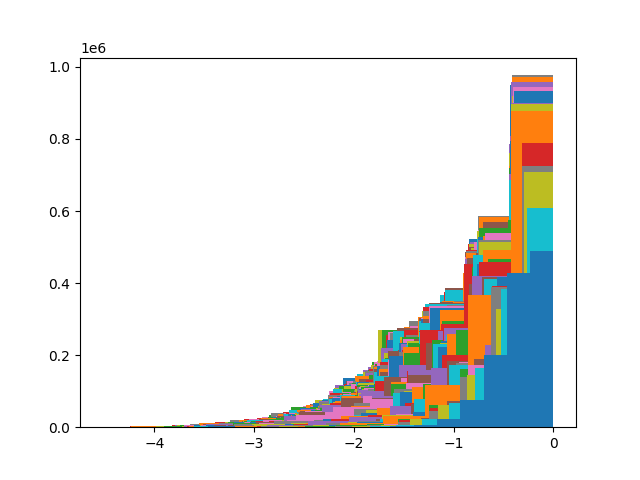
Distribution of values from computing dot product between patch feature and features from the feature field
Video from attempting to extract and render flower with threshold -0.5
Video from attempting to extract and render flower with threshold -1
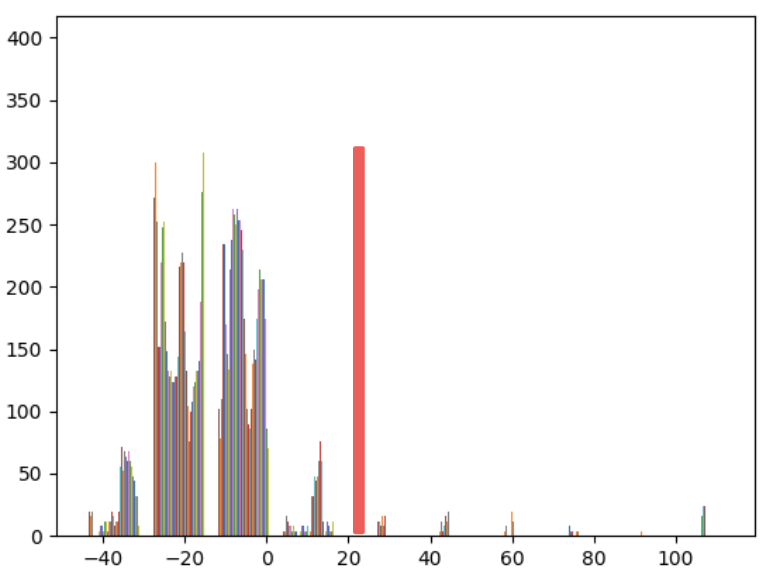
Extracting Features from 2D Image with Transparent Object
We use the same methodology to extract features from the 2D images containing a transparent object as we did in the opaque case. This example image is from the KeyPose dataset, and we use a threshold of 25 to extract the bottle from the image. Although the bottle is extracted correctly, the extracted image also includes areas of the bottle's shadow. This may be because the DINO feature vector is very similar for the bottle and its shadow.

Rendering Features from 3D Scene with Transparent Object
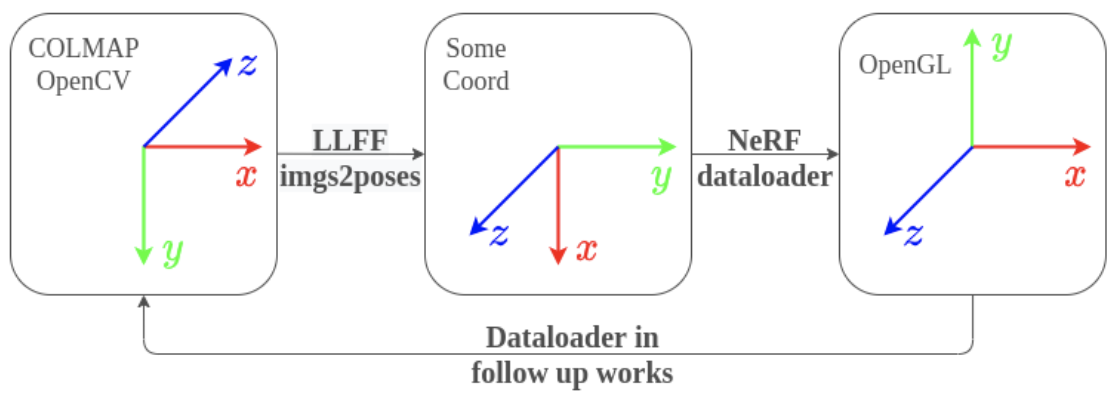
We attempted to extract and render transparent objects from 3D scenes using images from the KeyPose and Dex-NeRF datasets. We used the transforms matrix and camera intrinsics provided by both datasets. However, we believe that the poses for both of these datasets are in the format of the OpenCV coordinate system. We attempted to convert the rotation matrix for these datasets from OpenCV to the LLFF coordinate system because TensoRF converts from LLFF to NeRF coordinate system, as shown in the figure above. However, we found that the rendered video output on the transparent object datasets using our modified poses looks incorrect.
Rendered video output for images from KeyPose dataset
Rendered video output for images from Dex-NeRF dataset